



Attaching disk storage to containers
introduction of Volumes
Kubernetes volumes are one of the components of a pod and are defined in the pods specification like containers, volumes are not part of Kubernetes object and cannot be created or deleted on their own. A volume is available to all containers in the pod, but it should be mounted in each container that needs to access it. In each container, you can mount the volume in any location for eg: (var/lib/dir). Linux allows you to mount a filesystem at arbitrary locations in the file tree.
Introducing Available volume Types:
A wide variety of volume types is available. Several are generic, while others are similar to the actual storage technologies, Here is the list of several of the available volume types
emptyDIR------> A simple empty directory used for storing temparory data
hostpath -------> used for mounting directories from the worker node's file- system in to the pod
git-repo ---------> A volume initialized by checking out the contents of a Git-repo
nfs ---------------> An "nfs" share mounted into the pod
GCE ----------> Google compute engine persistent disk, Aws Elastic Block-store volume, (Microsoft Azure Disk Volume) -------> Used for mounting cloud provider-specific
Cinder, Cephfs, Iscsi, flocker, glusterfs, quobyte, rbd, flexvolume, vsphere volume, photonpersistennt disk, scaleIo ------> Used for mounting other types of network storage
Persistent volume claim --------> A way to use a pre or dynamically provisioned persistent storage.
Configuring a volume for a pod
In this section you will create a pod that runs one container. This pod has a volume of type "emptydir" it will be availble throughout the pod life, even if the container terminates and restarts. Here is the configuration file
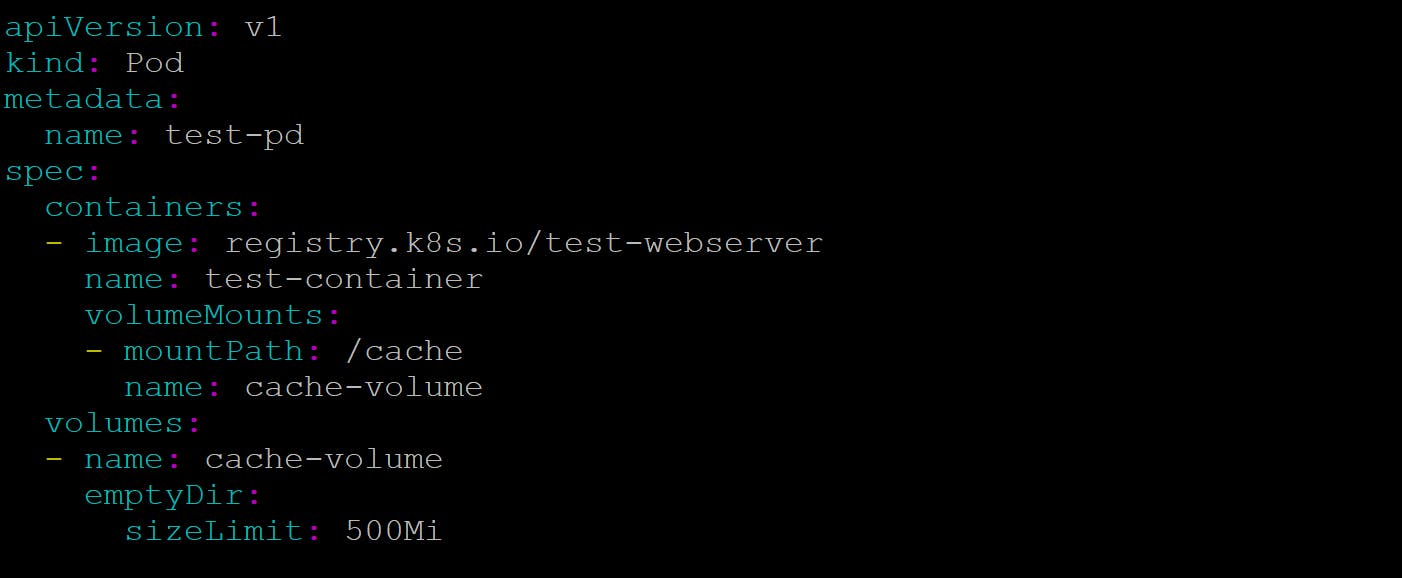
The emptyDir.medium field controls where emptyDir volumes are stored. By default emptyDir volumes are stored on whatever medium that backs the node such as disk, SSD, or network storage, depending on your environment. If you set the emptyDir.medium field to "Memory", Kubernetes mounts a tmpfs (RAM-backed filesystem) for you instead
Using volumes to share data between containers:
Normally volumes will be used by a single container, let's see how it's used for sharing data between multiple containers in a pod.
Building the nodejs container image:
create a new directory called k8s in that create one file with the name bin.sh

In that same directory, create a file called Dockerfile as shown below
output:
Now create a pod, A pod with two containers sharing the same volume
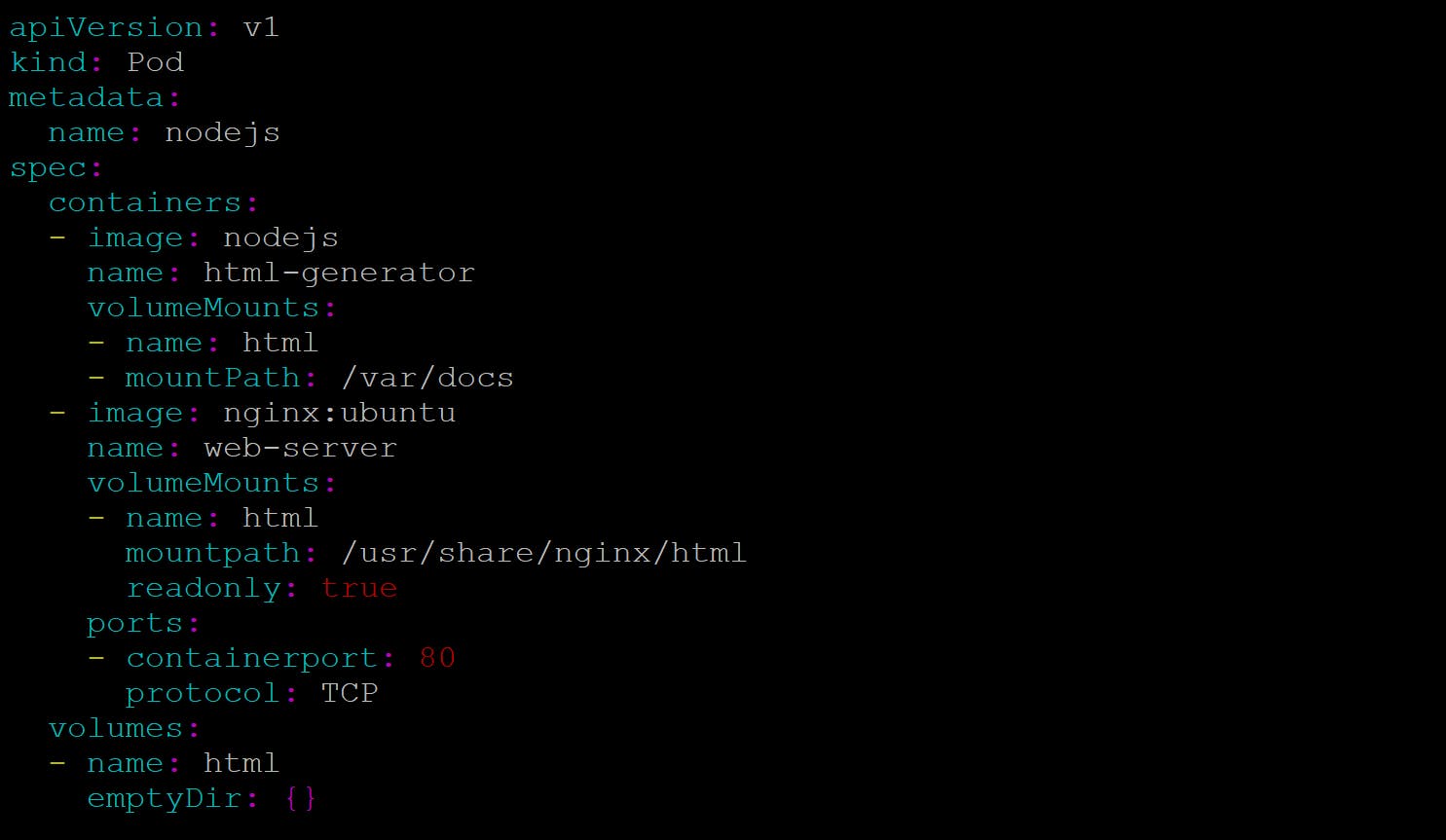
The pod contains two containers and a single volume that's mounted in both of them, yet a different paths. when the html generator container starts writin the output of the nodejs command to the var/docs/index.html file every 20 seconds, Because the volume is mounted at var/docs. in the same way when web-server container starts it's starts HTML files are in the /usr/share/nginx/html directory. Because you mounted the volume in that exact loation. At the end client send an http request to the pod on port 80 will recieve the current nodejs message as the response.
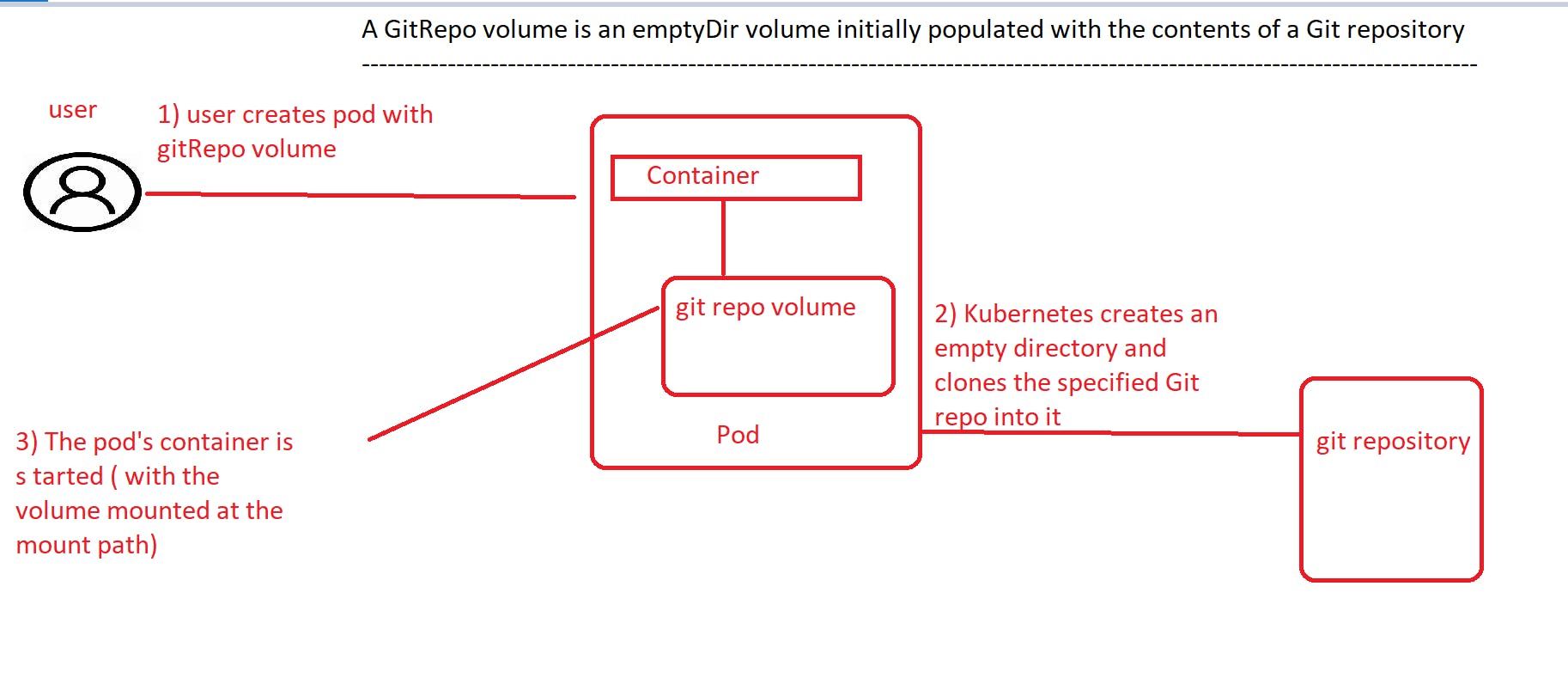
Using a Git repository as the starting point for a volume
A git repo volume is basically an emptyDir volume that gets populated by cloning a Git repository and checking out a specific revision when the pod is starting up.
NOTE: The gitRepo volume type is deprecated. To provision a container with a git repo, mount an EmptyDir into an InitContainer that clones the repo using git, then mount the EmptyDir into the Pod's container.
A gitRepo volume is an example of a volume plugin. This plugin mounts an empty directory and clones a git repository into this directory for your Pod to use
Running a Web-server Pod serving files from a cloned git repository
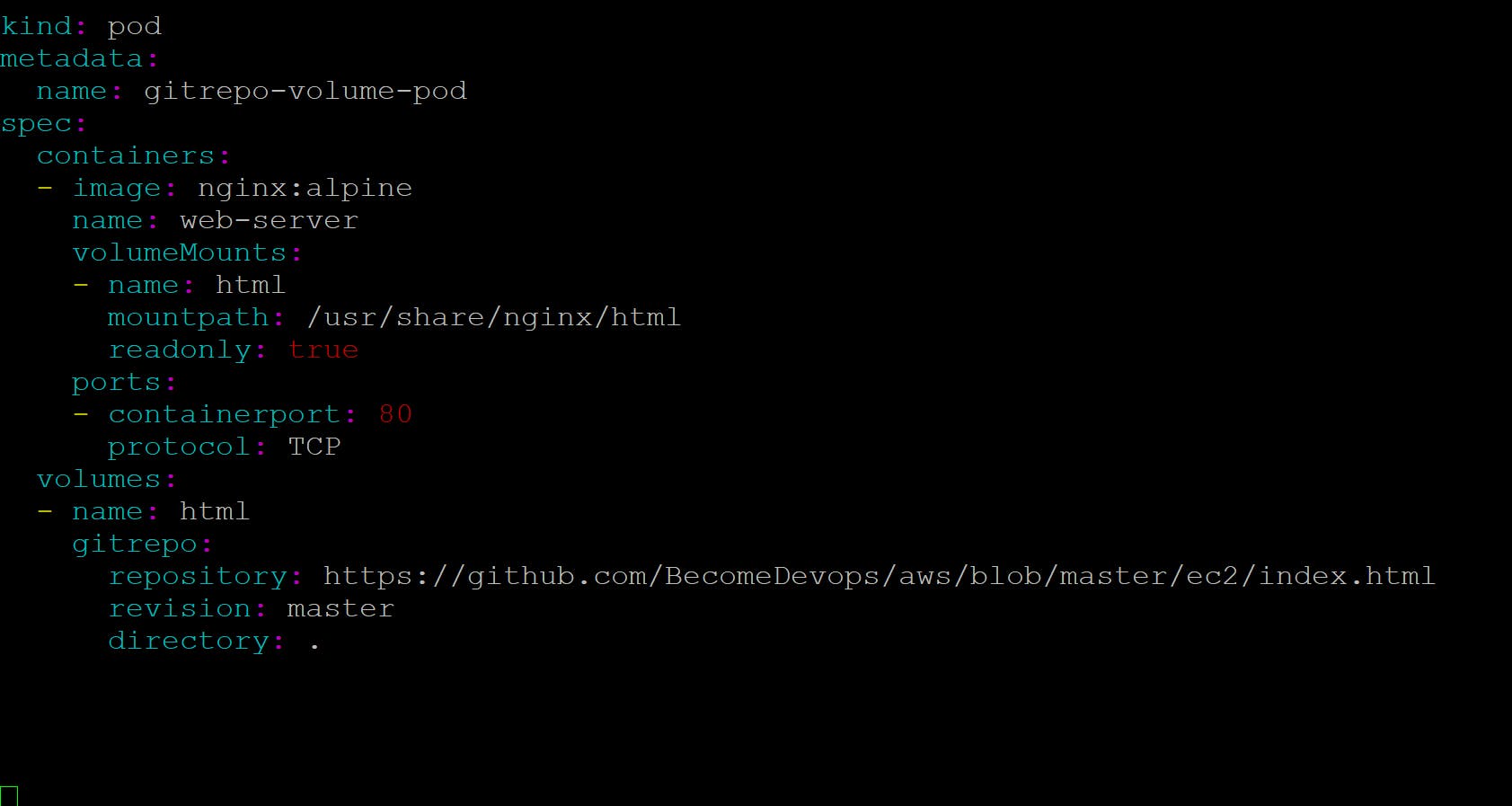
when you create a pod, the volume is first initialized as an empty directory and then the specified Git repository is cloned into it . Along with the repository, you also specified you want Kubernetes to to check out whatever revision the master branch is pointing to at the time the volume is created
Using persistent storage
when an appliation running in apod needs to persist data to disk and have that same data available even when the pod is rescheduled to another node
Decoupling pods from the underlying storage technology
All the persistent volume types have explored so far have required the developer of the pod, ideally a developer deploying their apps on Kubernetes should never have to know what kind of storage technologies is used, in the same way, they don't have to know what type of physical servers are being used to run their pods.
when a developer needs a certain amount of persistent storage for their application, they can request it from Kubernetes, the same way they can request CPU, Memory, and other resources when creating a pod. The system administrator can configure the cluster so it can give the apps what they request.
Introduction of persistent volumes and persistent volume claims
To enable apps to request storage in a kubernetes cluster without having to deal with infrastructure, two new resources are there 1) Persistent volumes & 2) Persistent volume claims. if you see before examples of regular kubernetes volumes can be used to store persistent data.
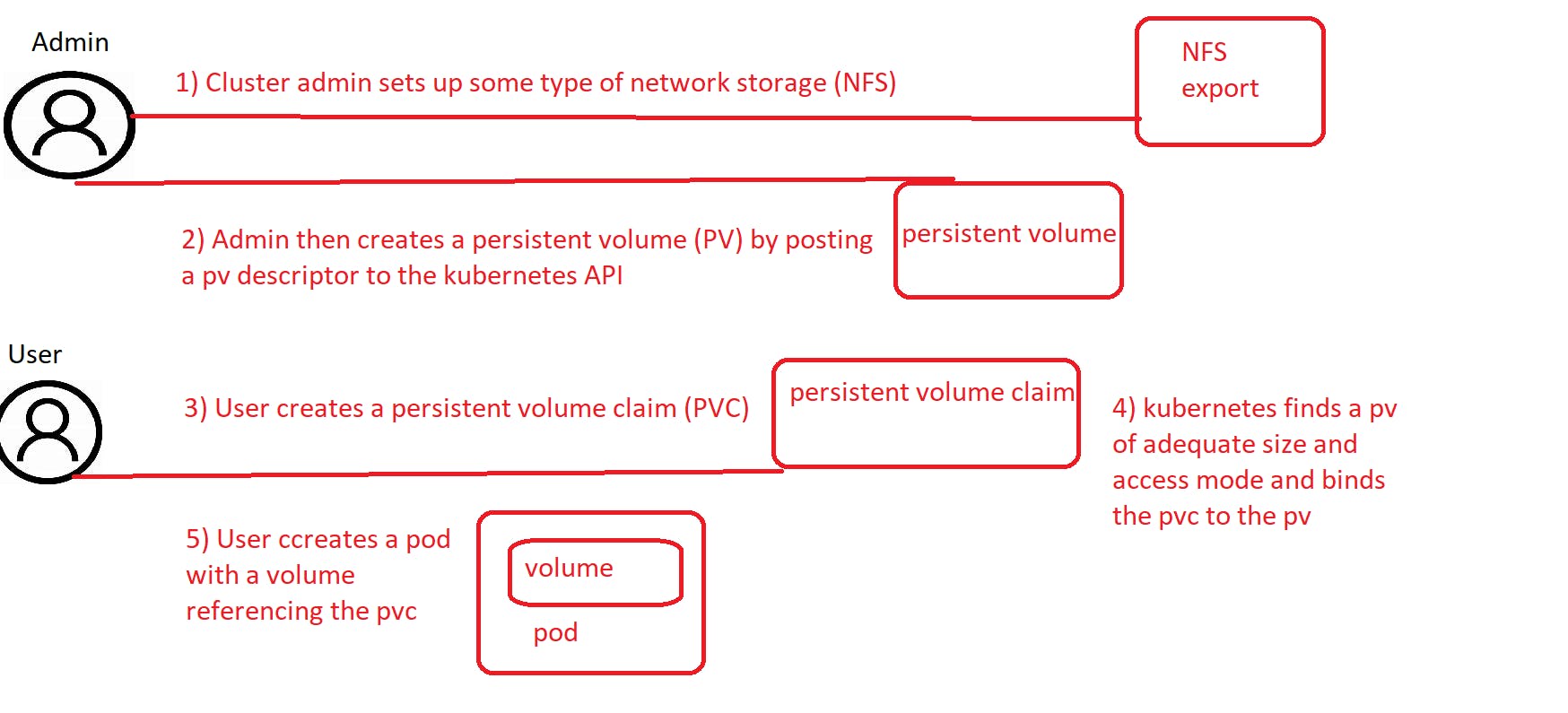
The Persistent Volume claim can then be used as one of the volumes inside a pod. other users cannot use the same persistent volume until it has been released by deleting the pod persistent volume claim.
create a persistent volume using the mongo-db-pv-host-path.yaml
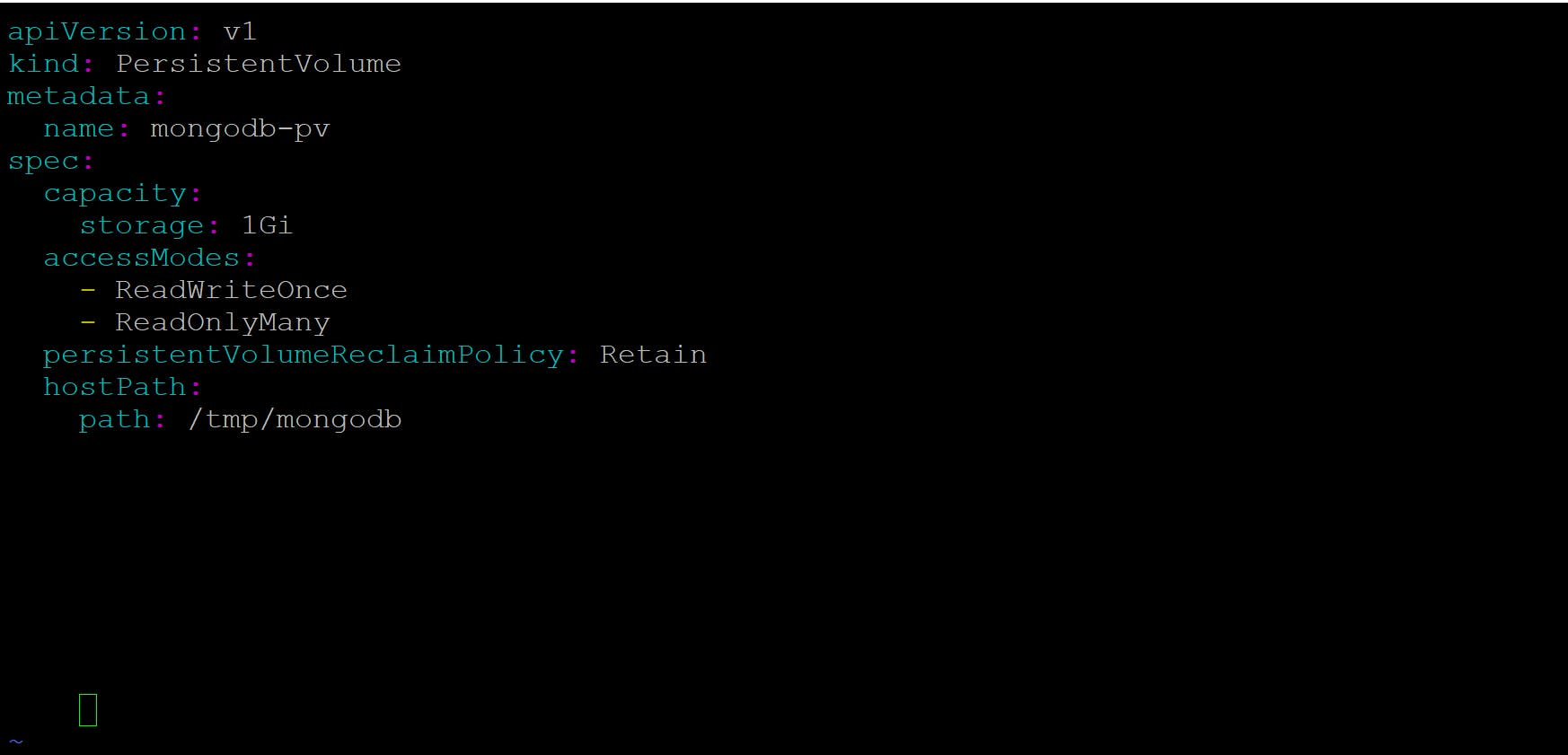
when creating a persistent volume, the administrator needs to tell kubernetes what its capacity is and where it can read or written to by a single node or by multiple nodes at the same time. They also need to tell kubernetes what to do with the persistent volume when it's released
After you create the persistent volume, it should be ready to claim as shown below

Note: Several columns are omitted. Also PV is used for persistent volume. persistent volumes don't belong to any namespaces. they are cluster-level resources like nodes